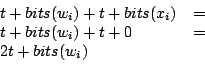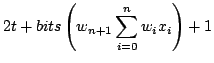Since the library should be written in ANSI C, the API needs to be a function based API, but there can still be an object oriented thought behind the API.
I will use an ANN structure, which can be allocated by a constructor and deallocated by a destructor. This structure should be given as the first argument to all functions which operates on the ANN, to mimic an object oriented approach.
The ANN should have three different methods of storing the internal weights: float, double and int. Where float and double are standard floating point representations and int is the fixed point representation. In order to give the compiler the best possible opportunity to optimize the code, this distinction should be made at compile-time. This will produce several different libraries and require that the person using the library should include a header file which is specific to the method chosen. Although there is this distinction between which header file is include, it should still be easy to write code which could compile with all three header files. For this purpose I have invented a fann_type, which is defined in the three header files as float, double and int respectively.
It should be possible to save the network in standard floating point representation and in fixed point representation (more on this in section 4.4).
Furthermore there should be a structure which could hold training data. This structure should like the net itself be loadable from a file. The structure of the file should be fairly simple, making it easy to export a file in this format from another program.
I will leave the rest of the API details to section 5 ``User's Guide''.
The data structures should be structured in three levels: A level containing the whole ANN, a level containing the layers and a level containing the neurons and connections.
With this three level structure, I will suggest two different implementations. The first is centered around the connections and the second is centered around the neurons.
Where the connection layers represent all the connections between two layers and the neurons themselves are only basic fann_type's. The main advantage of this structure is that one simple loop can run through all the connections between two layers. If these connections are allocated in one long array, the array can be processed completely sequentially. The neurons themselves are only basic fann_type's and since there are far less neurons than there are connections they do not take up that much space. This architecture is shown on figure 6.
![\includegraphics[width=0.9\textwidth]{figs/connection_centered.fig.eps}](img56.png) |
This was the first architecture which I implemented, but after testing it against Lightweight Neural Network version 0.3 [van Rossum, 2003], I noticed that this library was more than twice as fast as mine.
The question is now, why was the connection centered architecture not as fast as it should have been? I think the main reasons was that the connections, which is the most represented structure in ANNs, was implemented by a struct with two pointers and a weight. This took up more space than needed which meant poor cache performance. It also meant that the inner loop should constantly dereference pointers, which the compiler had no idea where would end up, although they where actually accessing the neurons in a sequential order.
![\includegraphics[width=0.9\textwidth]{figs/neuron_centered.fig.eps}](img57.png) |
![\includegraphics[width=\textwidth]{figs/architecture.fig.eps}](img58.png) |
Figure 8 illustrates how the architecture is connected at the third level. The neurons, the weights and the connections are allocated in three long arrays. A single neuron ![]() consists of a neuron value, two pointers and a value for the number of neurons connected to
consists of a neuron value, two pointers and a value for the number of neurons connected to ![]() in the previous layer. The first pointer points at the position in the weight array, which contain the first weight for the connections to
in the previous layer. The first pointer points at the position in the weight array, which contain the first weight for the connections to ![]() . Likewise the second pointer points to the first connection to
. Likewise the second pointer points to the first connection to ![]() in the connection array. A connection is simply a pointer to a neuron, in the previous layer, which is connected to
in the connection array. A connection is simply a pointer to a neuron, in the previous layer, which is connected to ![]() .
.
This architecture is more cache friendly, than the connection centered architecture. When calculating the input to a neuron, the weights, the connections and the input neurons are all processed sequentially. The value of the neuron itself is allocated in a local variable, which makes for much faster access. Furthermore, the weights and the connections are all processed completely sequentially, throughout the whole algorithm. When the ANN is fully connected, the array with the connected neurons is obsolete and the algorithms can use this to increase speed.
These algorithms are however not the only algorithms needed in this library.
The algorithm, which creates an ANN with a certain density ![]() , has a number of requirements which it must comply to:
, has a number of requirements which it must comply to:
The algorithm that I have constructed to do this is illustrated in algorithm 1. Because some connections should always be in place, the actual connection rate may be different than the connection rate parameter given.
This optimization has not been implemented because the activation function is only calculated once for each neuron and not once for each connection. The cost of the activation function becomes insignificant compared to the cost of the sum function, if fully connected ANNs become large enough.
The activation functions, that I have chosen to implement is the threshold function and the sigmoid function.
The general idea behind all of these suggestions, is the fact that you can calculate the maximum value that you will ever get as input to the activation function. This is done, by assuming that the input on each connection into a neuron is the worst possible and then calculating how high a value you could get.
Since all inputs internally in the network is an output from another activation function, you will always know which value is the worst possible value. The inputs on the other hand are not controlled in any way. In order to ensure that an integer overflow will never occur, you will have to put constraints on the inputs. There are several different kinds of constraints you could put on the inputs, but I think that it would be beneficial to put the same constraints on the inputs as on the outputs, implying that the input should be between zero and one. Actually this constraint can be relaxed to allow inputs between minus one and one.
I now have full control of all the variables and I will have to choose an implementation method for ensuring that integer overflow will not occur. There are two questions here which needs to be answered. The first is how should the decimal point be handled? But I will come to this in section 4.4.1.
The second is when and how the check be should made? An obvious choice would be to let the fixed point library make the check, as this library needs the fixed point functionality. However, this presents a problem because the fixed point library is often run on some kind of portable or embedded device. The floating point library, on the other hand, is often run on a standard workstation. This fact suggests that it would be useful to let the floating point library do all the hard work and simply let the fixed point library read a configuration file saved by the floating point library.
These choices make for a model, where the floating point library trains the ANN, then checks for the possibility of integer overflow and saves the ANN in a fixed point version. The fixed point library then reads this configuration file and can begin executing inputs.
There are two ways of determining the position of the decimal point. The first way, is to set the decimal point at compile time. The second is to set the decimal point when saving the ANN from the floating point library.
There are several advantages of setting the decimal point at compile time:
There are however also several advantages of setting the decimal point when saving the ANN to a fixed point configuration file:
Although there are less advantages in the last solution, it is the most general and scalable solution, therefore I will choose to set the decimal point when saving the ANN. The big question is now, where should the decimal point be? And how can you be absolutely sure that an integer overflow will not occur when the decimal point is there?
Before calculating where the decimal point should be, I will define what happens with the number of used bits under certain conditions: When multiplying two integer numbers, you will need the same number of bits to represent the result, as was needed to represent both of the multipliers. E.g. if you multiply two 8 bit numbers, you will get a 16 bit number [Pendleton, 1993]. Furthermore, when adding or subtracting two signed integers you will need as many bits as used in the largest of the two numbers plus one. When doing a fixed point division, you will need to shift the numerator left by as many bits as the decimal point. When doing a decimal point multiplication, you first do a standard integer multiplication and then shift right by as many bits as the decimal point.
Several operations has the possibility of generating integer overflow, when looking at what happens when executing an ANN with equation 2.5.
If ![]() is the number of bits needed for the fractional part of the fixed point number, we can calculate how many bits are needed for each of these operations. To help in these calculations, i will define the
is the number of bits needed for the fractional part of the fixed point number, we can calculate how many bits are needed for each of these operations. To help in these calculations, i will define the
![]() function, were
function, were ![]() is the number of bits used to represent the integer part of
is the number of bits used to represent the integer part of ![]() .
.
When calculating ![]() we do a fixed point multiplication with a weight and a number between zero and one. The number of bits needed in this calculation is calculated in equation 4.1.
we do a fixed point multiplication with a weight and a number between zero and one. The number of bits needed in this calculation is calculated in equation 4.1.
When calculating the activation function in fixed point numbers, it is calculated as a stepwise linear function. In this function the dominating calculation is a multiplication between a fixed point number between zero and one and the input to the activation function. From the input to the activation function another fixed point number is subtracted before the multiplication. The number of bits needed in this calculation is calculated in equation 4.2.
Since the highest possible output of the sum function is higher than the highest possible weight, this operation is the dominating operation. This implies, that if I can prove that an overflow will not occur in this operation, I can guarantee that an overflow will never occur.
When saving the ANN in the fixed point format, I can calculate the number of bits used for the integer part of the largest possible value that the activation function can be given as a parameter. This value is named ![]() in equation 4.3, which calculates the position of the decimal point
in equation 4.3, which calculates the position of the decimal point ![]() for a
for a ![]() bit signed integer (remembering that one bit is needed for the sign).
bit signed integer (remembering that one bit is needed for the sign).
The library is written in ANSI C which puts some limitations on a programmer like me, who normally codes in C++. However, this is not an excuse for writing ugly code, although allocating all variables at the beginning of a function will never be pretty.
I have tried to use comprehensible variable and function names, I have also tried only using standard C functions, in order to make the library as portable as possible. I have made sure that I did not create any global variables and that all global functions or macros was named in a way, so that they would not easily interfere with other libraries (by adding the name fann). Furthermore, I have defined some macros which are defined differently in the fixed point version and in the floating point version. These macros help writing comprehensible code without too many #ifdef's.
Steffen Nissen 2003-11-07
![\begin{algorithm}
% latex2html id marker 368
[htb]
\begin{algorithmic}
\REQUIRE...
...t represented in this algorithm in order to make it more simple.}\end{algorithm}](img60.png)