In order to understand ANN, you will need to have a basic knowledge of how the internals of the brain work. The brain is part of the central nervous system and consists of a very large NN. The NN is actually quite complicated, but I will only include the details needed to understand ANN, in order to simplify the explanation.
The NN is a network consisting of connected neurons. The center of the neuron is called the nucleus. The nucleus is connected to other nucleuses by means of the dendrites and the axon. This connection is called a synaptic connection.
The neuron can fire electric pulses through its synaptic connections, which is received at the dendrites of other neurons. Figure 1 shows how a simplified neuron looks like.
When a neuron receives enough electric pulses through its dendrites, it activates and fires a pulse through its axon, which is then received by other neurons. In this way information can propagate through the NN. The synaptic connections change throughout the lifetime of a neuron and the amount of incoming pulses needed to activate a neuron (the threshold) also change. This behavior allows the NN to learn.
The human brain consists of around ![]() neurons which are highly interconnected with around
neurons which are highly interconnected with around ![]() connections [Tettamanzi and Tomassini, 2001]. These neurons activates in parallel as an effect to internal and external sources. The brain is connected to the rest of the nervous system, which allows it to receive information by means of the five senses and also allows it to control the muscles.
connections [Tettamanzi and Tomassini, 2001]. These neurons activates in parallel as an effect to internal and external sources. The brain is connected to the rest of the nervous system, which allows it to receive information by means of the five senses and also allows it to control the muscles.
ANNs are not intelligent, but they are good for recognizing patterns and making simple rules for complex problems. They also have excellent training capabilities which is why they are often used in artificial intelligence research.
ANNs are good at generalizing from a set of training data. E.g. this means an ANN given data about a set of animals connected to a fact telling if they are mammals or not, is able to predict whether an animal outside the original set is a mammal from its data. This is a very desirable feature of ANNs, because you do not need to know the characteristics defining a mammal, the ANN will find out by itself.
![]() is a neuron with
is a neuron with ![]() input dendrites
input dendrites
![]() and one output axon
and one output axon ![]() and where
and where
![]() are weights determining how much the inputs should be weighted.
are weights determining how much the inputs should be weighted.
![]() is an activation function that weights how powerful the output (if any) should be from the neuron, based on the sum of the input. If the artificial neuron should mimic a real neuron, the activation function
is an activation function that weights how powerful the output (if any) should be from the neuron, based on the sum of the input. If the artificial neuron should mimic a real neuron, the activation function ![]() should be a simple threshold function returning 0 or 1. This is however, not the way artificial neurons are usually implemented. For many different reasons it is smarter to have a smooth (preferably differentiable) activation function. The output from the activation function is either between 0 and 1, or between -1 and 1, depending on which activation function is used. This is not entirely true, since e.g. the identity function, which is also sometimes used as activation function, does not have these limitations, but most other activation functions uses these limitations. The inputs and the weights are not restricted in the same way and can in principle be between
should be a simple threshold function returning 0 or 1. This is however, not the way artificial neurons are usually implemented. For many different reasons it is smarter to have a smooth (preferably differentiable) activation function. The output from the activation function is either between 0 and 1, or between -1 and 1, depending on which activation function is used. This is not entirely true, since e.g. the identity function, which is also sometimes used as activation function, does not have these limitations, but most other activation functions uses these limitations. The inputs and the weights are not restricted in the same way and can in principle be between ![]() and
and ![]() , but they are very often small values centered around zero. The artificial neuron is also illustrated in figure 2.
, but they are very often small values centered around zero. The artificial neuron is also illustrated in figure 2.
In the figure of the real neuron (figure 1), the weights are not illustrated, but they are implicitly given by the number of pulses a neuron sends out, the strength of the pulses and how closely connected the neurons are.
As mentioned earlier there are many different activation functions, some of the most commonly used are threshold (2.2), sigmoid (2.3) and hyperbolic tangent (2.4).
Where ![]() is the value that pushes the center of the activation function away from zero and
is the value that pushes the center of the activation function away from zero and ![]() is a steepness parameter. Sigmoid and hyperbolic tangent are both smooth differentiable functions, with very similar graphs, the only major difference is that hyperbolic tangent has output that ranges from -1 to 1 and sigmoid has output that ranges from 0 to 1. A graph of a sigmoid function is given in figure 3, to illustrate how the activation function look like.
is a steepness parameter. Sigmoid and hyperbolic tangent are both smooth differentiable functions, with very similar graphs, the only major difference is that hyperbolic tangent has output that ranges from -1 to 1 and sigmoid has output that ranges from 0 to 1. A graph of a sigmoid function is given in figure 3, to illustrate how the activation function look like.
The ![]() parameter in an artificial neuron can be seen as the amount of incoming pulses needed to activate a real neuron. This parameter, together with the weights, are the parameters adjusted when the neuron learns.
parameter in an artificial neuron can be seen as the amount of incoming pulses needed to activate a real neuron. This parameter, together with the weights, are the parameters adjusted when the neuron learns.
Multilayer feedforward ANNs have two different phases: A training phase (sometimes also referred to as the learning phase) and an execution phase. In the training phase the ANN is trained to return a specific output when given a specific input, this is done by continuous training on a set of training data. In the execution phase the ANN returns outputs on the basis of inputs.
The way the execution of a feedforward ANN functions are the following: An input is presented to the input layer, the input is propagated through all the layers (using equation 2.1) until it reaches the output layer, where the output is returned. In a feedforward ANN an input can easily be propagated through the network and evaluated to an output. It is more difficult to compute a clear output from a network where connections are allowed in all directions (like in the brain), since this will create loops. There are ways of dealing with these loops in recurrent networks, ([Hassoun, 1995] p. 271) describes how recurrent networks can be used to code time dependencies, but feedforward networks are usually a better choice for problems that are not time dependent.
Figure 4 shows a multilayer feedforward ANN where all the neurons in each layer are connected to all the neurons in the next layer. This is called a fully connected network and although ANNs do not need to be fully connected, they often are.
Two different kinds of parameters can be adjusted during the training of an ANN, the weights and the ![]() value in the activation functions. This is impractical and it would be easier if only one of the parameters should be adjusted. To cope with this problem a bias neuron is invented. The bias neuron lies in one layer, is connected to all the neurons in the next layer, but none in the previous layer and it always emits 1. Since the bias neuron emits 1 the weights, connected to the bias neuron, are added directly to the combined sum of the other weights (equation 2.1), just like the
value in the activation functions. This is impractical and it would be easier if only one of the parameters should be adjusted. To cope with this problem a bias neuron is invented. The bias neuron lies in one layer, is connected to all the neurons in the next layer, but none in the previous layer and it always emits 1. Since the bias neuron emits 1 the weights, connected to the bias neuron, are added directly to the combined sum of the other weights (equation 2.1), just like the ![]() value in the activation functions. A modified equation for the neuron, where the weight for the bias neuron is represented as
value in the activation functions. A modified equation for the neuron, where the weight for the bias neuron is represented as ![]() , is shown in equation 2.5.
, is shown in equation 2.5.
Adding the bias neuron allows us to remove the ![]() value from the activation function, only leaving the weights to be adjusted, when the ANN is being trained. A modified version of the sigmoid function is shown in equation 2.6.
value from the activation function, only leaving the weights to be adjusted, when the ANN is being trained. A modified version of the sigmoid function is shown in equation 2.6.
We cannot remove the ![]() value without adding a bias neuron, since this would result in a zero output from the sum function if all inputs where zero, regardless of the values of the weights. Some ANN libraries do however remove the
value without adding a bias neuron, since this would result in a zero output from the sum function if all inputs where zero, regardless of the values of the weights. Some ANN libraries do however remove the ![]() value without adding bias neurons, counting on the subsequent layers to get the right results. An ANN with added bias neurons is shown in figure 5.
value without adding bias neurons, counting on the subsequent layers to get the right results. An ANN with added bias neurons is shown in figure 5.
Where ![]() is the number of connections,
is the number of connections, ![]() is the total number of neurons,
is the total number of neurons, ![]() is the number of input and bias neurons,
is the number of input and bias neurons, ![]() is the cost of multiplying the weight with the input and adding it to the sum,
is the cost of multiplying the weight with the input and adding it to the sum, ![]() is the cost of the activation function and
is the cost of the activation function and ![]() is the total cost.
is the total cost.
If the ANN is fully connected, ![]() is the number of layers and
is the number of layers and ![]() is the number of neurons in each layer (not counting the bias neuron), this equation can be rewritten to:
is the number of neurons in each layer (not counting the bias neuron), this equation can be rewritten to:
This equation shows that the total cost is dominated by ![]() in a fully connected ANN. This means that if we want to optimize the execution of a fully connected ANN, we need to optimize
in a fully connected ANN. This means that if we want to optimize the execution of a fully connected ANN, we need to optimize ![]() and retrieval of the information needed to compute
and retrieval of the information needed to compute ![]() .
.
The training process can be seen as an optimization problem, where we wish to minimize the mean square error of the entire set of training data (for further information on the mean square error see section 5.3.3). This problem can be solved in many different ways, ranging from standard optimization heuristics like simulated annealing, through more special optimization techniques like genetic algorithms to specialized gradient descent algorithms like backpropagation.
The most used algorithm is the backpropagation algorithm (see section 2.3.1), but this algorithm has some limitations concerning, the extent of adjustment to the weights in each iteration. This problem has been solved in more advanced algorithms like RPROP [Riedmiller and Braun, 1993] and quickprop [Fahlman, 1988], but I will not elaborate further on these algorithms.
Although we want to minimize the mean square error for all the training data, the most efficient way of doing this with the backpropagation algorithm, is to train on data sequentially one input at a time, instead of training on the combined data. However, this means that the order the data is given in is of importance, but it also provides a very efficient way of avoiding getting stuck in a local minima.
I will now explain the backpropagation algorithm, in sufficient details to allow an implementation from this explanation:
First the input is propagated through the ANN to the output. After this the error ![]() on a single output neuron
on a single output neuron ![]() can be calculated as:
can be calculated as:
Where ![]() is the calculated output and
is the calculated output and ![]() is the desired output of neuron
is the desired output of neuron ![]() . This error value is used to calculate a
. This error value is used to calculate a ![]() value, which is again used for adjusting the weights. The
value, which is again used for adjusting the weights. The ![]() value is calculated by:
value is calculated by:
Where ![]() is the derived activation function. The need for calculating the derived activation function was why I expressed the need for a differentiable activation function in section 2.2.1.
is the derived activation function. The need for calculating the derived activation function was why I expressed the need for a differentiable activation function in section 2.2.1.
When the ![]() value is calculated, we can calculate the
value is calculated, we can calculate the ![]() values for preceding layers. The
values for preceding layers. The ![]() values of the previous layer is calculated from the
values of the previous layer is calculated from the ![]() values of this layer. By the following equation:
values of this layer. By the following equation:
Where ![]() is the number of neurons in this layer and
is the number of neurons in this layer and ![]() is the learning rate parameter, which determines how much the weight should be adjusted. The more advanced gradient descent algorithms does not use a learning rate, but a set of more advanced parameters that makes a more qualified guess to how much the weight should be adjusted.
is the learning rate parameter, which determines how much the weight should be adjusted. The more advanced gradient descent algorithms does not use a learning rate, but a set of more advanced parameters that makes a more qualified guess to how much the weight should be adjusted.
Using these ![]() values, the
values, the ![]() values that the weights should be adjusted by, can be calculated by:
values that the weights should be adjusted by, can be calculated by:
The
![]() value is used to adjust the weight
value is used to adjust the weight ![]() , by
, by
![]() and the backpropagation algorithm moves on to the next input and adjusts the weights according to the output. This process goes on until a certain stop criteria is reached. The stop criteria is typically determined by measuring the mean square error of the training data while training with the data, when this mean square error reaches a certain limit, the training is stopped. More advanced stopping criteria involving both training and testing data are also used.
and the backpropagation algorithm moves on to the next input and adjusts the weights according to the output. This process goes on until a certain stop criteria is reached. The stop criteria is typically determined by measuring the mean square error of the training data while training with the data, when this mean square error reaches a certain limit, the training is stopped. More advanced stopping criteria involving both training and testing data are also used.
In this section I have briefly discussed the mathematics of the backpropagation algorithm, but since this report is mainly concerned with the implementation of ANN algorithms, I have left out details unnecessary for implementing the algorithm. I will refer to [Hassoun, 1995] and [Hertz et al., 1991] for more detailed explanation of the theory behind and the mathematics of this algorithm.
If the ANN is fully connected, the running time of algorithms on the ANN is dominated by the operations executed for each connection (as with execution of an ANN in section 2.2.3).
The backpropagation is dominated by the calculation of the ![]() and the adjustment of
and the adjustment of ![]() , since these are the only calculations that are executed for each connection. The calculations executed for each connection when calculating
, since these are the only calculations that are executed for each connection. The calculations executed for each connection when calculating ![]() is one multiplication and one addition. When adjusting
is one multiplication and one addition. When adjusting ![]() it is also one multiplication and one addition. This means that the total running time is dominated by two multiplications and two additions (three if you also count the addition and multiplication used in the forward propagation) per connection. This is only a small amount of work for each connection, which gives a clue to how important it is, for the data needed in these operations to be easily accessible.
it is also one multiplication and one addition. This means that the total running time is dominated by two multiplications and two additions (three if you also count the addition and multiplication used in the forward propagation) per connection. This is only a small amount of work for each connection, which gives a clue to how important it is, for the data needed in these operations to be easily accessible.
Steffen Nissen 2003-11-07
![\includegraphics[width=0.6\textwidth]{figs/neuron.fig.eps}](img5.png)

![\includegraphics[width=0.45\textwidth]{figs/artificial_neuron.fig.eps}](img17.png)
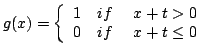
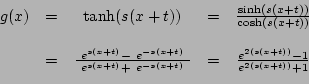
![\includegraphics[width=0.6\textwidth]{figs/sigmoid.fig.eps}](img21.png)
![\includegraphics[width=0.6\textwidth]{figs/feedforward.fig.eps}](img22.png)
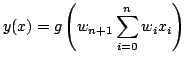
![\includegraphics[width=0.6\textwidth]{figs/feedforward_bias.fig.eps}](img26.png)
